Podman und Kubernetes sind zwei Systeme, die im gleichen technologischen Ökosystem existieren, aber unterschiedliche Rollen einnehmen. Podman setzt auf maximale Nähe zum Linux-Kernel, daemonlose Ausführung und einen klar nachvollziehbaren Prozessbaum. Kubernetes hingegen ist ein hochgradig verteiltes Orchestrierungssystem, das Container als abstrakte Workloads behandelt. Die spannende Frage ist daher nicht, ob Podman ein Ersatz für Kubernetes ist – das ist es nicht –, sondern wie Podman und Kubernetes sich ergänzen, ineinandergreifen und an welchen Stellen sie sich konzeptuell berühren.
Podman ist eine Container-Engine. Sie startet Container, verwaltet Pod-Strukturen, managt Storage, Netzwerke und Images. Kubernetes arbeitet auf einer höheren Abstraktionsebene. Dort werden Pods, Deployments, ReplicaSets und Services modelliert – aber Kubernetes selbst startet keine Container. Diese Aufgabe delegiert Kubernetes an sogenannte CRI-Engines.
Historisch sah die Landschaft so aus:
Podman ist bewusst nicht CRI-kompatibel. Die Frage, ob Kubernetes „Podman spricht“, ist daher technisch klar mit „nein“ zu beantworten. Aber Podman besitzt andere Eigenschaften, die Kubernetes-ähnliche Workflows ermöglichen.
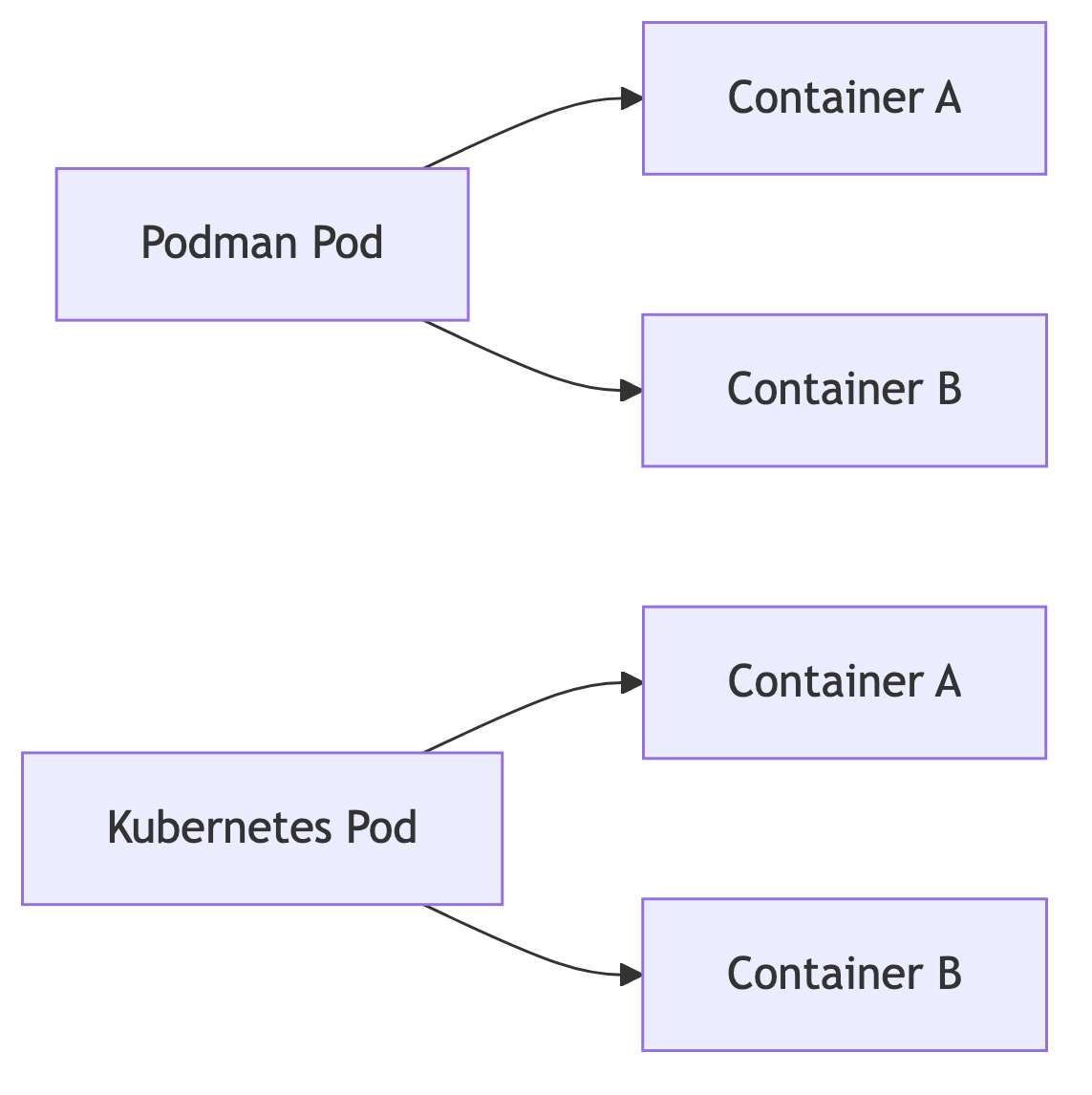
Podman implementiert Pods – und zwar mit einem Modell, das sich an Kubernetes-Pods anlehnt. Die Idee:
In Kubernetes ist der Pod die kleinste deploybare Einheit. Podman übernimmt genau diese Semantik auf Ein-Node-Ebene und bildet damit ein Mini-Orchestrierungsmodell.
Ein Diagramm zur Gegenüberstellung:
Konzeptionell sind die Strukturen ähnlich – die Umgebungen jedoch radikal verschieden: Podman verwaltet Pods lokal, Kubernetes verteilt Pods über Cluster.
Diese Gemeinsamkeit macht Podman zu einem praktikablen Werkzeug für Entwickler, die Kubernetes-Workloads lokal reproduzieren möchten. Ohne Minikube, ohne Kind, ohne K3s. Ein einfacher Podman-Pod kann oft das Verhalten eines Kubernetes-Pods nachbilden – vor allem:
Wer beispielsweise einen API-Server mit einem Log-Agent und einem Monitoring-Sidecar entwickeln möchte, kann dies in Podman als Pod modellieren – ohne Cluster, ohne Control Plane.
Podman bietet eine Funktion, die oft übersehen wird:
podman generate kube <pod>Dieser Befehl erstellt aus einem Podman-Pod ein Kubernetes-kompatibles YAML:
Das YAML ist nicht für unmittelbare Produktion geeignet, aber es ist erstaunlich nah an Kubernetes-Standards. Ideal für:
Ein Beispieltypischer Ablauf:
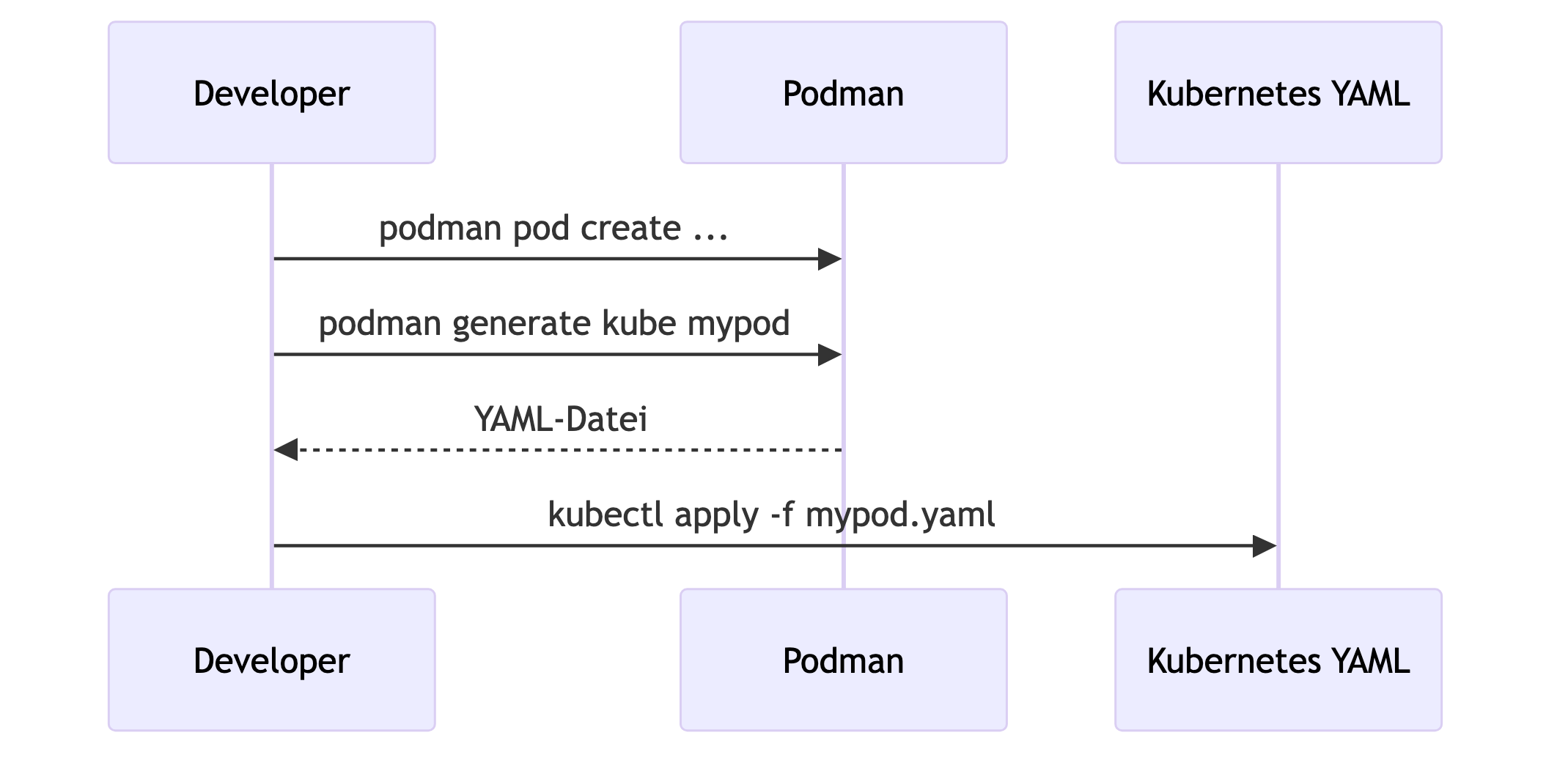
Podman wird hier zu einem Werkzeug zur YAML-Generierung, nicht zum Kubernetes-Laufzeitbackend.
Mit Podman Desktop wurde die Distanz zwischen Podman und Kubernetes weiter überbrückt. Podman Desktop bietet:
Dadurch wird ein nahtloser Übergang ermöglicht: Container lokal bauen → in Podman testen → in Kubernetes deployen.
Die Schnittstelle bleibt dabei klar: Kubernetes läuft mit containerd oder CRI-O, nicht mit Podman selbst.
CRI-O ist eine Schwestertechnologie von Podman. Beide nutzen dieselben Komponenten:
Der Unterschied:
In vielen Red Hat Enterprise Linux-Umgebungen sieht man daher:
Kubernetes Cluster
→ CRI-O als Runtime
→ Podman für lokale Workloads des AdministratorsBeide Tools teilen sich einen Großteil des Codes, erfüllen aber unterschiedliche Rollen.
Podman kann nicht:
Dafür ist Kubernetes gebaut.
Aber Podman kann:
Während Kubernetes horizontal skaliert, skaliert Podman vertikal – innerhalb eines Hosts.
Entwickler nutzen Podman für:
Architekten nutzen Podman für:
Kubernetes übernimmt:
Beide Systeme ergänzen sich – Podman ist ein lokales, kernelnahes Werkzeug; Kubernetes ist ein orchestrierender Meta-Layer.
Wer Podman versteht, versteht viele Kubernetes-Konzepte instinktiv:
Und umgekehrt gilt: Wer Kubernetes-Workloads modellieren kann, kommt mit Podman sehr schnell zurecht.

Podman ist daher nicht „kleines Kubernetes“, sondern ein Werkzeug, um die Konzepte von Kubernetes vollständig lokal zu praktizieren.
Podman und Kubernetes sind zwei Seiten desselben Ökosystems. Sie sind keine Alternativen zueinander, sondern unterschiedliche Ebenen: Podman als lokale, transparente Runtime; Kubernetes als verteiltes Managementsystem.