Containerisierung wird häufig als ein homogener technologischer Block wahrgenommen – ein Image wird gebaut, ein Container wird gestartet, ein Cluster verteilt Workloads. Doch diese Sichtweise vermischt zwei strikt getrennte Klassen von Systemen: Container-Engines und Orchestratoren. Beide bilden zusammen das Fundament moderner Cloud-, Edge- und On-Premise-Infrastrukturen, erfüllen jedoch völlig unterschiedliche Aufgaben, sprechen unterschiedliche Schnittstellen und operieren auf unterschiedlichen Abstraktionsebenen. Die exakte Abgrenzung ist essenziell, um Architekturentscheidungen fundiert treffen zu können.
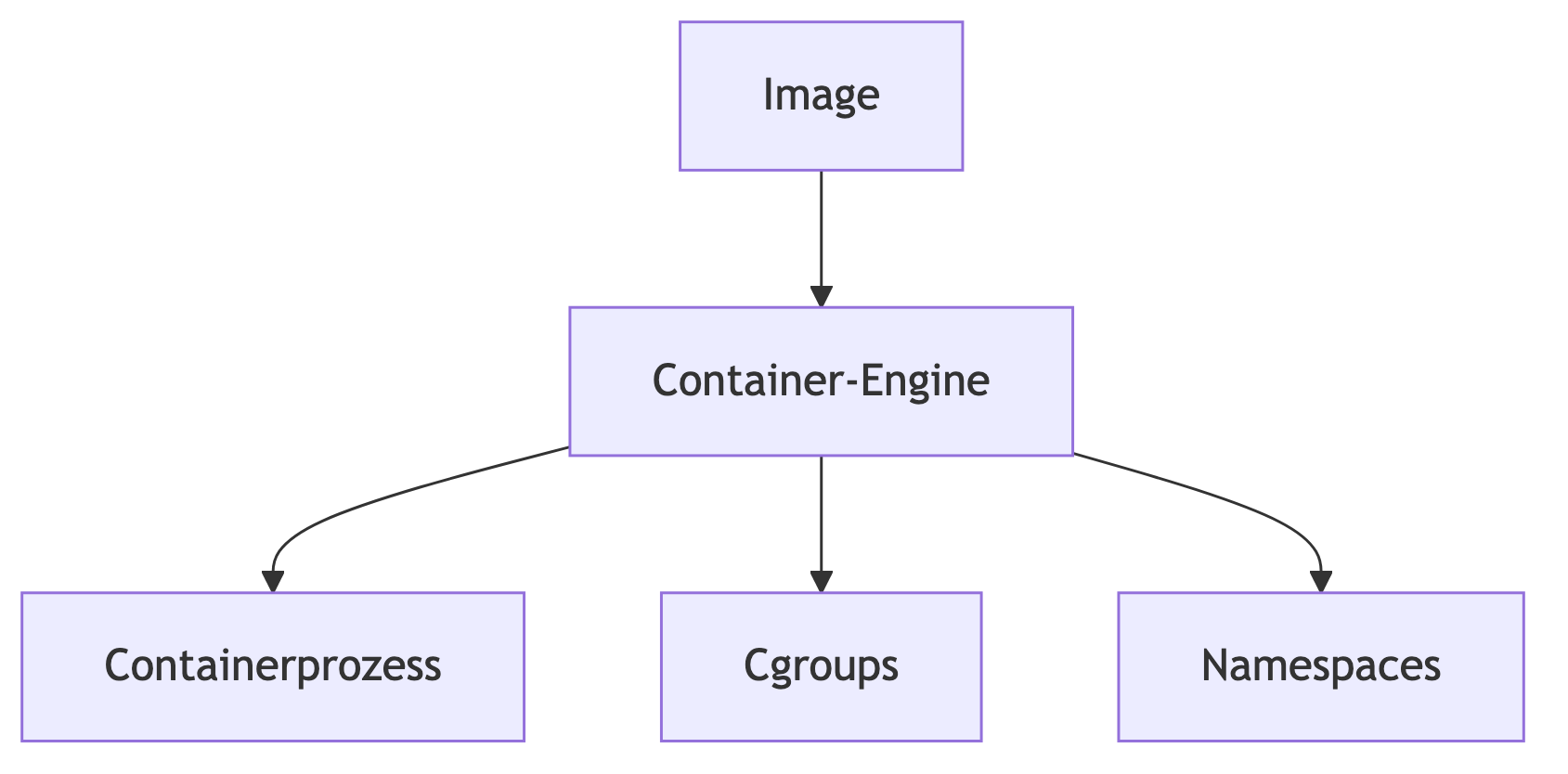
Eine Container-Engine kümmert sich um die Ausführung einzelner Container. Ihre Hauptaufgabe ist nicht das Management großer Systemlandschaften, sondern die präzise Kontrolle einzelner Prozesse in einem isolierten Namespace-Verbund.
Typische Vertreter:
Eine Engine führt Containerprozesse aus und kapselt sie über:
Engines sprechen in der Regel kein verteiltes Protokoll. Sie arbeiten lokal auf einem Host und verwalten Ressourcen innerhalb dieses einen Systems. Ihr Denken ist prozesszentriert.
Ein abstrahiertes Engine-Modell:
Die Engine beantwortet Fragen wie:
Sie beantwortet nicht die Fragen:
Genau dafür existiert die Orchestrierungsschicht.
Ein Orchestrator behandelt Container als Workloads in einem Cluster. Er denkt nicht in Prozessen, sondern in gewünschten Systemzuständen („desired state“).
Typische Orchestratoren:
Ein Orchestrator benötigt mindestens:
Funktionsbereiche:
Ein Orchestrator arbeitet auf einer deklarativen Ebene:
kubectl apply -f deployment.yamlDer Benutzer beschreibt einen gewünschten Zustand, der Orchestrator stellt diesen Zustand her – und hält ihn stabil, selbst wenn Nodes ausfallen.
Ein typisches Orchestrator-Modell:
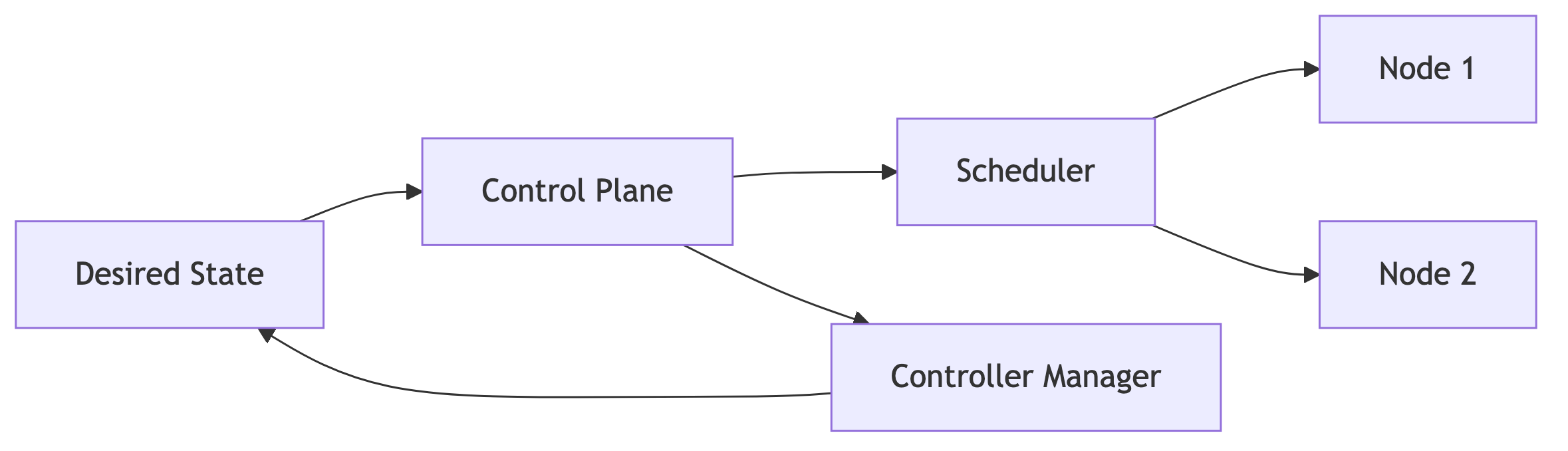
Der Orchestrator hat ein zentrales Ziel: Clusterstabilität und Lastverteilung. Er führt keine Container aus – er delegiert an die Engine.
Eine Container-Engine:
Eine Engine ist ein Werkzeug für:
Sie bietet kein verteiltes Verhalten – und soll das auch gar nicht.
Ein Orchestrator:
Ein Orchestrator ist ein Systemsteuerer, kein Prozessstarter.
Man kann es sich so merken:
Das Zusammenspiel lässt sich klar in Schichten darstellen:
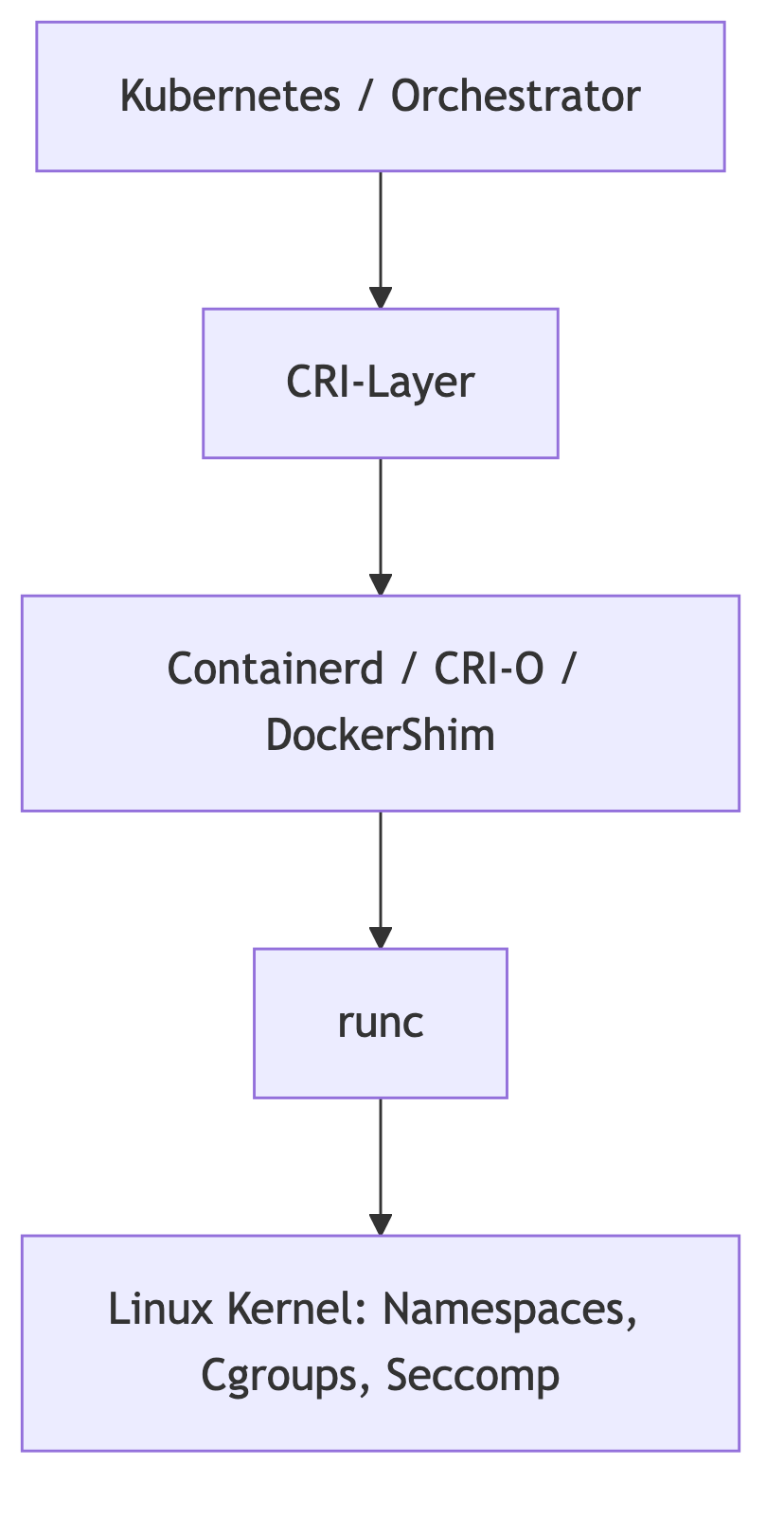
Podman passt hier bewusst nicht in die CRI-Schicht, weil es nicht für Kubernetes entworfen wurde. Podman operiert als alternative Engine für Menschen – nicht für Maschinen.
Podman kann Pods erzeugen – aber ohne Scheduling, ohne Cluster-Kontext und ohne Multi-Node-Verteilung. Pods in Podman sind eine lokale Gruppierung von Containern, kein Distributed System. Sie ähneln Kubernetes-Pods nur in der konzeptionellen Struktur, nicht in der operativen Logik.
Podman-Pod:
Kubernetes-Pod:
Die Namensähnlichkeit führt leicht zu Fehlinterpretationen. Die Semantik ist jedoch klar unterschiedlich.
Viele Fehlentscheidungen entstehen, wenn die Ebenen verwechselt werden:
Eine Engine löst das Problem der sicheren Prozessisolation. Ein Orchestrator löst das Problem der verteilten Anwendungssteuerung.
Beides zusammen ergibt moderne Container-Infrastruktur – aber nur dann, wenn man die Rollen klar trennt und richtig einordnet.
Die Abgrenzung zwischen Container-Engine und Orchestrator ist daher kein theoretisches Detail, sondern ein pragmatisches Fundament: Engines betreiben Container. Orchestratoren betreiben Systeme, die Container betreiben.