Restart-Strategien sind ein fundamentaler Bestandteil robuster Linux-Dienste. Sie definieren, wie systemd auf Fehler, Abbrüche, Zeitüberschreitungen oder externe Signale reagiert. In produktionsnahen Systemen ist die Restart-Policy genauso wichtig wie das eigentliche Startkommando. Sie entscheidet darüber, ob ein Dienst zuverlässig verfügbar bleibt, ob er im Crashfall sauber regeneriert wird oder ob er sich bei hartnäckigen Fehlern selbst „totläuft“. Gerade beim Betrieb von Containern, Microservices und Backend-Prozessen ist die Wahl der richtigen Restart-Strategie ein zentrales Architekturdetail.
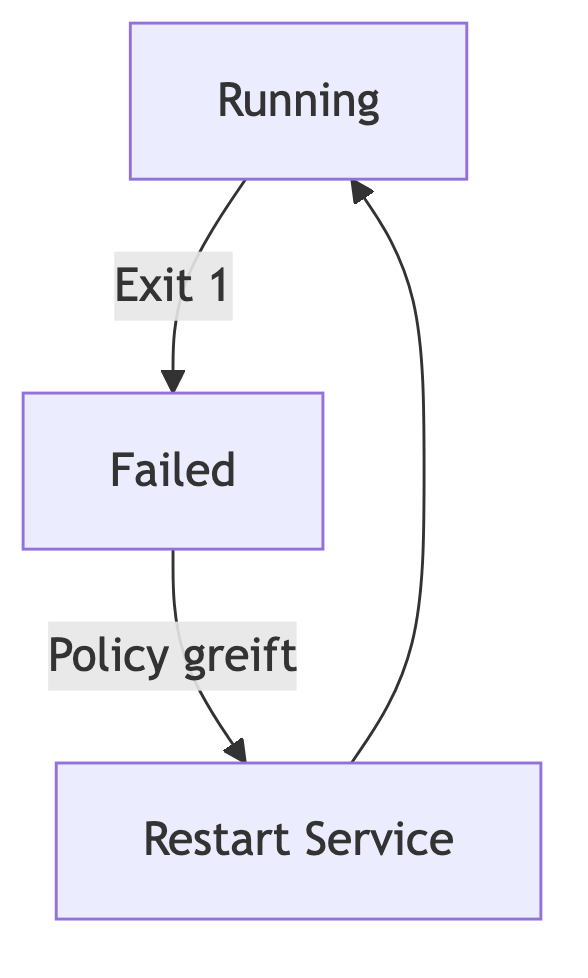
Ein Dienst existiert nicht nur in den Phasen „Start“ und „Stop“. Er durchläuft Zustände:
systemd modelliert diese Zustände explizit und macht sie über Restart-Strategien kontrollierbar. Ein Restart ist keine Notmaßnahme, sondern ein geplantes Verhalten.
Ein abstrahierter Ablauf:
systemd kennt mehrere grundlegende Restart-Modi. Jeder Modus besitzt eine klare Semantik:
Der Dienst wird immer neu gestartet, unabhängig vom Exit-Code.
Restart=alwaysEinsatzgebiet: persistent laufende Services wie Webserver, Datenbanken, Container, Worker.
Restartet nur, wenn der Prozess abnormal beendet wurde – Exit-Code ≠ 0, Signal, Crash.
Restart=on-failureEinsatzgebiet: Dienste, die im Erfolgsfall regulär beenden dürfen, aber bei Fehlern erneut laufen sollen.
Nur bei abnormalen Beendigungen: Crash, OOM-Killer, Signale.
Restart=on-abnormalRestart, wenn das Programm mit einem Signal terminiert wird, das nicht abgefangen wurde.
Restart=on-abortWird selten genutzt, aber manchmal praktisch: Dienst wird neu gestartet, wenn er erfolgreich beendet wurde.
Restart=on-successKein automatischer Restart.
Restart=noAm besten geeignet für One-Shot-Jobs, einmalige Konfigurationstasks, Migrationsskripte.
Restart-Prozesse benötigen Delays. Ohne sie kommt es zu „Restart-Stürmen“, bei denen systemd einen flackernden Service dutzende Male pro Sekunde startet. Das ist ineffizient und kann Logfiles, Kernelspace oder Netzwerkressourcen überlasten.
RestartSec=5Systemd wartet 5 Sekunden vor jedem Restart-Versuch. Für containerisierte Anwendungen ist dieser Wert besonders wichtig, weil Images initialisieren müssen, Netzwerke hochkommen oder Datenbanken bereit sein müssen.
Diese Parameter verhindern Eskalationsschleifen.
StartLimitIntervalSec=30
StartLimitBurst=5Bedeutung:
Ergebnis:
systemctl status myservice
→ Start request repeated too quickly.Diese Mechanik schützt das System und erleichtert Diagnose: Wenn ein Dienst dauerhaft crasht, fällt er nicht still in eine Endlosschleife.
Restart-Strategien funktionieren im User-Scope identisch wie im globalen Systemkontext. Ein wesentlicher Unterschied:
Das bedeutet, dass ein fehlerhafter rootless Container nicht das gesamte System belastet, sondern nur die Ressourcen seines Besitzers.
Für rootless Container, die Podman über systemd betreiben, empfiehlt sich meist:
Restart=always
RestartSec=2Damit erhält man robuste, langfristig stabile containerisierte Services.
Restart-Policies leben nicht isoliert. Sie interagieren mit dem Dependency-Modell von systemd.
Ein Beispiel:
Requires=postgresql.service
After=postgresql.serviceWenn PostgreSQL während des Betriebs neu startet, beeinflusst das
unter Umständen auch abhängige Services. Wenn ein Backend z. B. durch
die DB-Down-Phase crasht, sorgt Restart=always dafür, dass
es nach dem DB-Recovery automatisch wieder hochkommt.
Das Zusammenspiel lässt sich grafisch verdeutlichen:
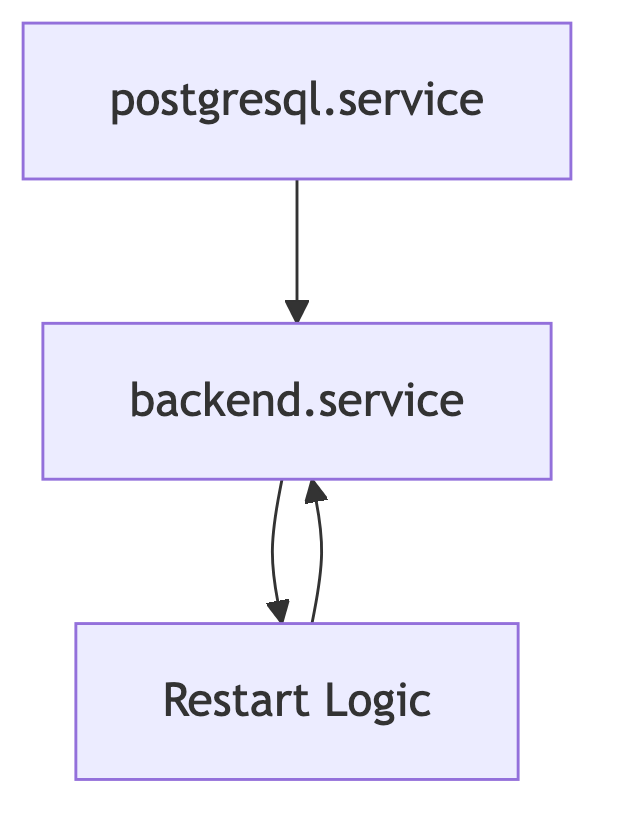
Persistente Systeme bestehen aus Ketten robuster Einzelkomponenten, deren Restart-Verhalten bewusst entworfen ist.
Für Podman gilt: systemd ist der Supervisor, nicht Podman selbst. Container-Units enthalten klare Restart-Kommandos:
ExecStop=/usr/bin/podman stop -t 10 backend
ExecStart=/usr/bin/podman run ...
Restart=alwaysPodman kümmert sich um den Container, systemd um dessen Lebenszyklus. Fällt der Containerprozess aus, sieht systemd das als normalen Prozess-Exit – und startet ihn gemäß Policy neu.
In Pod-Units:
ExecStart=/usr/bin/podman pod start mypod
ExecStop=/usr/bin/podman pod stop -t 10 mypod
Restart=on-failureHier greift die Restart-Strategie für den gesamten Pod, nicht für die einzelnen Container. Restarting ist also hierarchisch:
Ein präziser Blick auf Exit-Codes ist notwendig:
Restart=on-failure reagiert nur auf „Fehler“, nicht auf
reguläre Exits. Wer möchte, dass ein Worker endless läuft, wählt
besser:
Restart=alwaysFür kurzlebige Batch-Prozesse dagegen ist sinnvoll:
Type=oneshot
RemainAfterExit=yes
Restart=noDienste, die in Crashloops geraten, erzeugen Muster im Journal. Ein praktisches Diagnosefragment:
journalctl -u myservice.service -n 50systemd markiert Crash-Zyklen sichtbar:
Service has entered a failed state.
Start request repeated too quickly.Crashloops entstehen fast immer durch:
Professionelle Setups legen daher bewusst moderate Restart-Zeiten fest.
Restart-Strategien sind damit ein präzises Steuerinstrument für robuste Dienste. Sie verbinden die Prozesslaufzeit mit definierter Betriebskontrolle – und bilden den zentralen Baustein für ausfallsichere, nachvollziehbar gesteuerte Service-Lifecycles.