Containerisierung besteht aus zwei deutlich getrennten Schichten:
Container-Engines, die Container auf einem einzelnen Host starten und verwalten, und Orchestratoren, die Container über viele Hosts hinweg koordinieren.
Genau diese Trennung wird in der Praxis häufig verwischt. Viele technische Diskussionen überspringen die Engine-Ebene und springen gedanklich direkt zu Kubernetes. Dabei ist die Engine die Grundlage, auf der sämtliche Runtime-Prozesse aufbauen – egal ob auf einer einzelnen Workstation oder in einem großen Cluster.
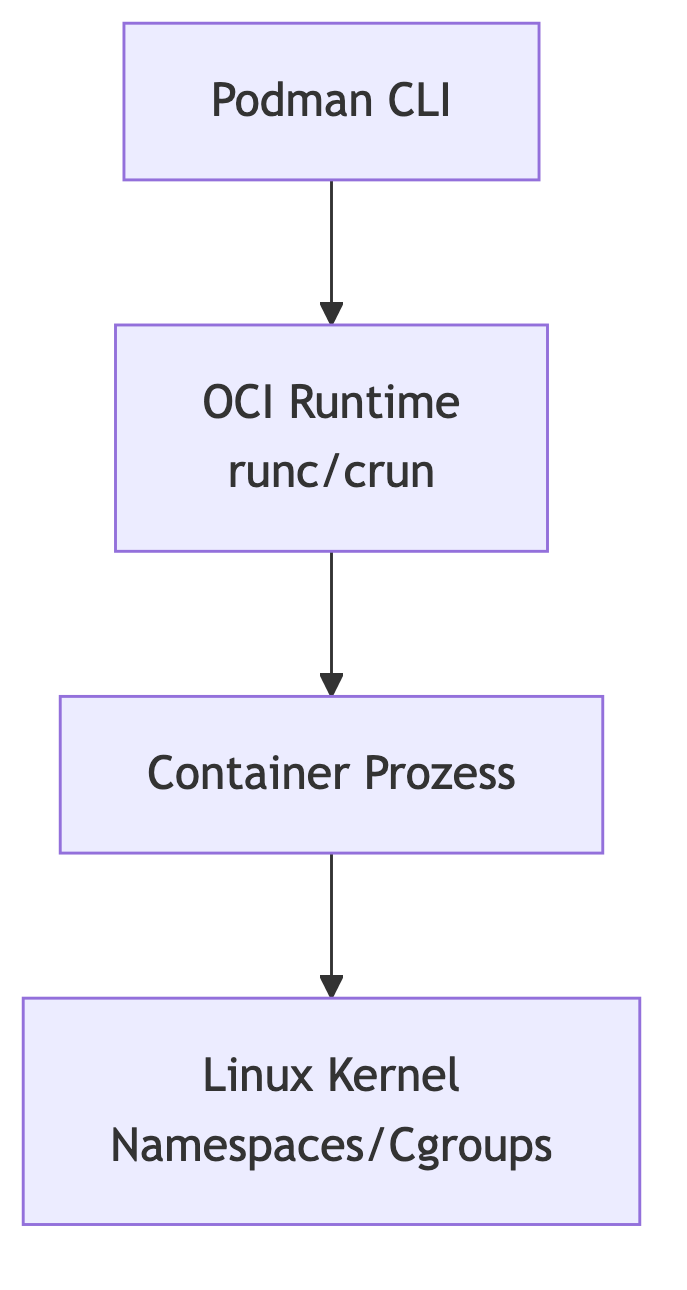
Podman bewegt sich vollständig auf dieser unteren Ebene. Es ist ein Werkzeug für einzelne Maschinen, nicht für Mehrknotenarchitekturen. Kubernetes hingegen interessiert sich nicht für das Starten einzelner Container, sondern für Zustände, Skalierung, Rollouts und Cluster-Scheduling.
Eine anschauliche Analogie: Podman ist der Motor eines Fahrzeugs, Kubernetes die Verkehrsleitstelle eines ganzen Straßennetzes.
Die Hauptaufgabe einer Container-Engine besteht darin, einzelne Containerprozesse zu starten, Ressourcen zuzuweisen und deren Lebenszyklus zu kontrollieren. Dazu gehören:
Podman erledigt diese Aufgaben direkt aus der CLI heraus, ohne einen Daemon. Dadurch verhält sich ein Podman-basierter Container im Prozessbaum wie ein reguläres Linux-Programm.
Die Engine ist nah an der Maschine. Keine Magie, keine Hidden Middle Layer.
Kubernetes arbeitet auf einer völlig anderen Abstraktionsebene. Es besitzt keine eingebaute Container-Engine und führt selbst keine Container aus. Stattdessen nutzt Kubernetes eine CRI-konforme Runtime, beispielsweise CRI-O oder containerd.
Die Kernaufgaben eines Orchestrators:
Die Engine ist nur ein Adapter im Gesamtgefüge – eine Art „Container-Treiber“.
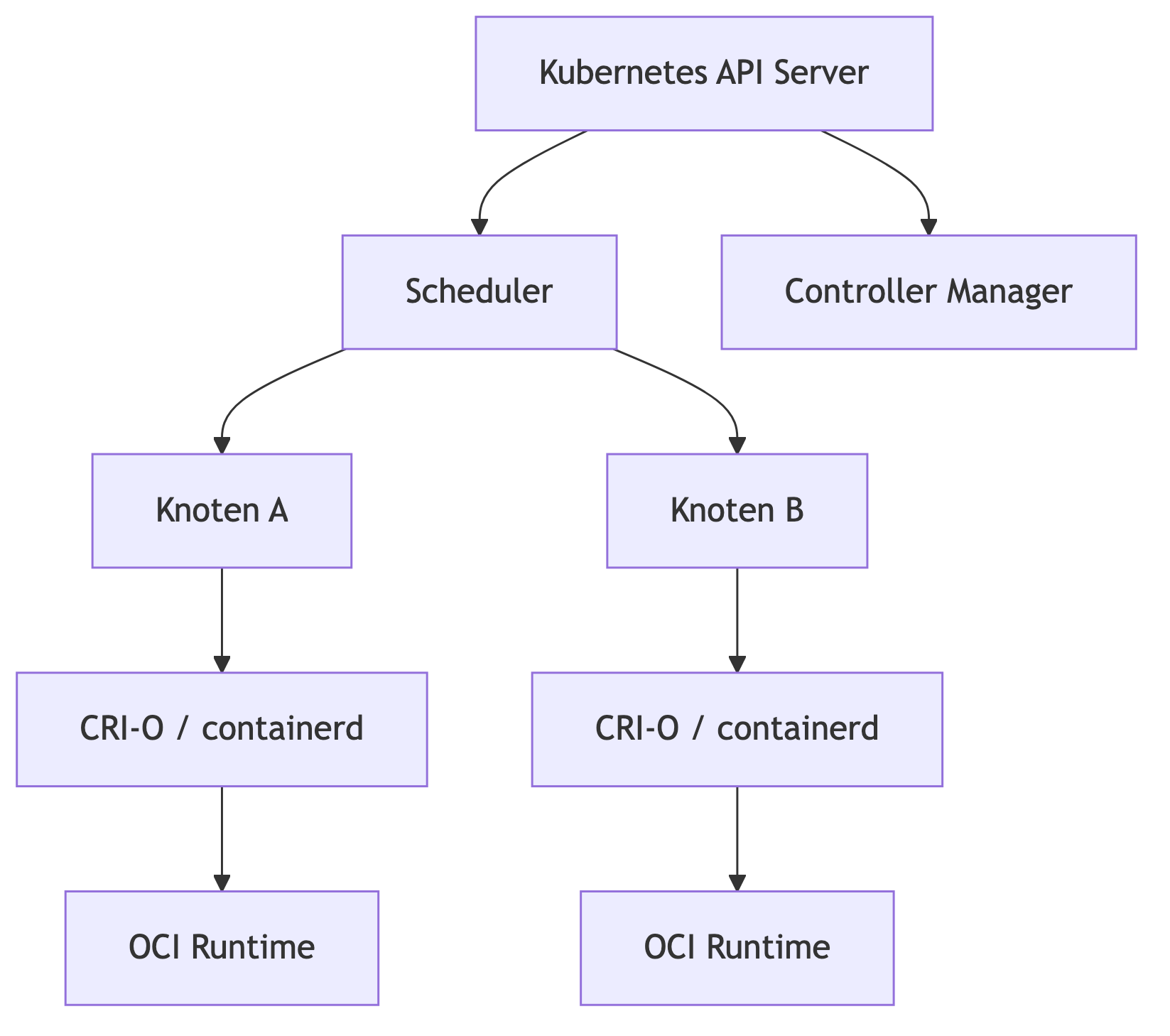
Kubernetes kümmert sich nicht um die Frage, wie ein Container gestartet wird, sondern wo und in welchem Zustand er sich befinden soll.
Da Podman Pods unterstützen kann und YAML-Dateien generiert, sorgt dieser Umstand regelmäßig für Missverständnisse. Der Pod-Begriff stammt ursprünglich aus Kubernetes, wurde aber von Podman lediglich als lokale Gruppierungsmechanik übernommen. Podman-Pods sind:
Podman kann YAML-Dateien erzeugen, die Kubernetes verstehen würde, doch das ersetzt keine Orchestrierung. Es handelt sich um eine Brücke, nicht um eine Abkürzung.
Podman eignet sich für Einzelknoten, Prototyping, Edge-Deployments oder Workloads, die lokal entwickelt oder getestet werden sollen. Der Schritt zu Kubernetes erfolgt erst, wenn Skalierungs-, Replikations- oder Scheduling-Probleme ins Spiel kommen.
Podman bewegt sich im OCI-Standardumfeld und erzeugt Images, die nahtlos in CRI-O oder containerd laufen. Damit eignet es sich hervorragend als Entwicklerwerkzeug, das dieselben Images erzeugt, die später im Cluster verwendet werden. Proprietäre Layer-Metadaten müssen nicht berücksichtigt werden.
Die Kubernetes-Unterstützung in Podman – konkret
podman generate kube und podman play kube –
ist als Werkzeug zur Annäherung zu verstehen. Praktisch für lokale
Experimente, aber kein Ersatz für eine deklarative Steuerung über einen
echten Orchestrator.
In einer realen Umgebung bilden Engine und Orchestrator eine durchgängige Linie, aber keine Einheit. Die Engine ist die Runtime, der Orchestrator das Steuerwerk. Erst gemeinsam ergibt sich ein vollständiges Bild:
Diese beiden Perspektiven sollte man sauber getrennt halten, um die Rollen im Stapel richtig zu verstehen – unabhängig davon, wie komplex oder einfach der konkrete Einsatzzweck ist.