Troubleshooting im Containerumfeld verlangt ein präzises Verständnis der darunterliegenden Linux-Mechanismen und des Systemverhaltens. Podman – als daemonlose Engine – bringt eine besonders transparente Fehlerdiagnostik mit sich: Alles, was passiert, ist ein normaler Hostprozess unter direkter Kontrolle des Kernels. Doch Transparenz allein löst keine Probleme; sie muss strukturiert genutzt werden. Dieses Kapitel beschreibt Methoden, Werkzeuge und Denkmodelle für eine professionelle Diagnose von Container- und Pod-Problemen in Podman-basierten Umgebungen.
Der wichtigste Grundsatz: Container sind Prozesse. Ein Fehler in einem Container ist in aller Regel ein Fehler im Prozess – oder in dessen Umgebung. Diese Perspektive unterscheidet Podman signifikant von Docker: Es gibt keinen Daemon, der Fehler verschluckt oder abstrahiert. Alle Probleme sind valide Linux-Probleme und lassen sich entsprechend untersuchen.
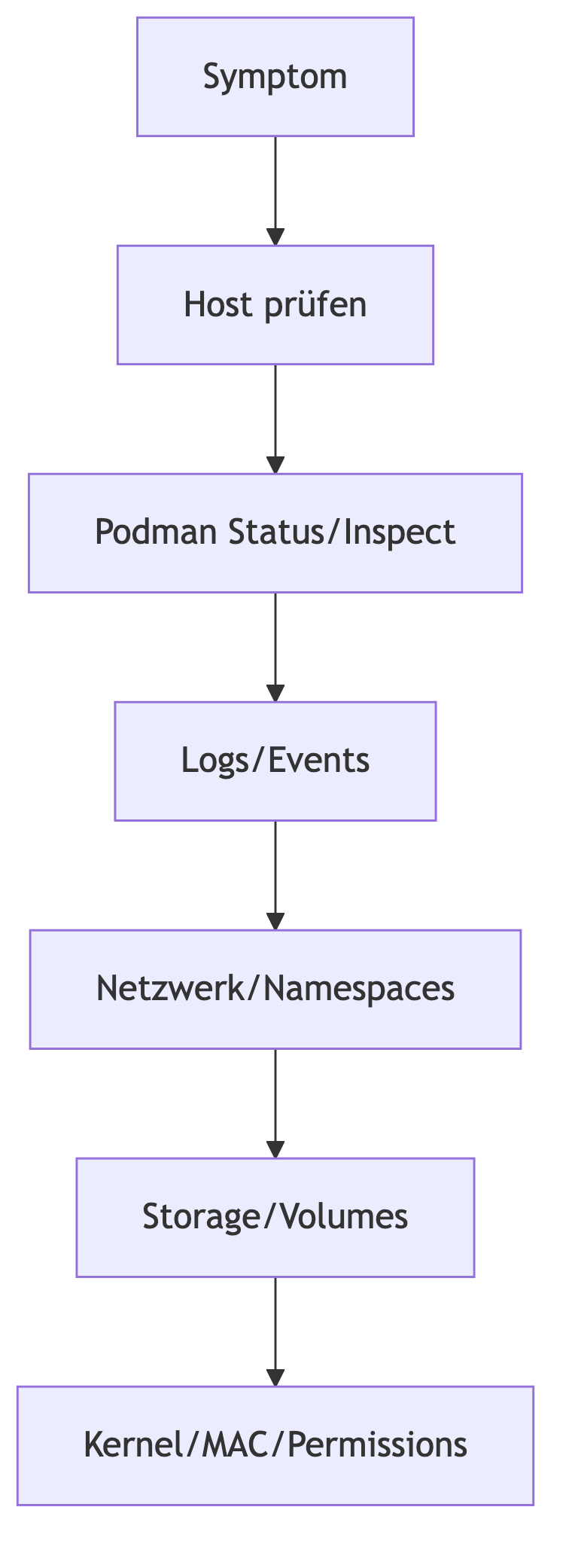
Ein systematischer Ablauf:
Troubleshooting verläuft entlang dieser Ebenen – vom Sichtbaren zum Systemkern.
Podman selbst bietet eine Reihe diagnostischer Kommandos, die häufig unterschätzt werden:
podman inspect <container|pod>Inspect liefert:
Inspect ist das „Röntgenbild“ der Containerstruktur. Viele Fehler liegen bereits hier offen:
Mounts fehlen oder sind falsch gelabeltentrypoint-/command-Angabenpodman logs <container>Ob trivial oder tiefgreifend: Logs zeigen fast immer die erste Spur.
Typische Beispiele:
Logs sind nicht nur Ausgaben, sondern Bestätigungen darüber, dass der Container überhaupt gestartet wurde.
podman eventsPodman protokolliert:
Events ermöglichen es, Muster zu erkennen – z. B. regelmäßige
Restarts durch falsche --restart-Policies oder
cgroup-OOM-Ereignisse.
Netzwerkprobleme sind die häufigste Fehlerquelle. Die Diagnose beginnt mit:
podman network inspect <network>Hier stehen:
Wenn ein Container „niemals erreichbar“ ist, steckt fast immer ein Namespace- oder Routingproblem dahinter.
podman exec <container> ip addr
podman exec <container> ip routeDiese Befehle zeigen:
Ein häufiges Problem ist, dass Anwendungen auf 127.0.0.1
lauschen, obwohl sie in Containerumgebungen an 0.0.0.0
binden müssen.
nsenter --net=/proc/<PID>/ns/netDamit wird der Netzwerk-Namespace des Containers betreten. Ideal für tiefe Fehlersuche.
Viele Probleme entstehen durch Storage:
podman inspect --format '{{.GraphDriver.Data}}' <container>ls -lZ /pfad/zum/volumeWenn der Kontext nicht container_file_t oder passend
gelabelt ist, verweigert SELinux alle Schreiboperationen.
Ein typischer Logeintrag:
permission denied (13)Die Ursache: SELinux – nicht fehlende UNIX-Berechtigungen.
Container, die „grundlos sterben“, tun dies oft wegen OOM-Killer oder Cgroup-Limits.
podman statsZeigt:
OOM-Killer-Ereignisse sieht man in:
dmesg | grep -i killoder im modernen Journal:
journalctl -kEin Container, der wegen OOM gestoppt wurde, zeigt in Podman oft nur einen „139“-Exitcode (Segfault-ähnlich).
Ein unschlagbarer Vorteil von Podman:
ps, top,
strace oder perfBeispiele:
ps auxf | grep <container-id>strace -p <PID>Dies identifiziert:
perf top -p <PID>Ideal für Performanceprobleme in containerisierten Anwendungen.
Pod-Fehler entstehen häufig durch falsches Zusammenspiel der Container:
Diagnose:
podman pod inspect <pod>
podman pod logs <pod>Ein Pod kann „running“ sein, während Container darin crashen. Podman zeigt das klar – anders als manche orchestratorbasierte Tools.
Wenn Podman-Container als Dienste laufen:
systemctl --user status mycontainer.service
journalctl --user -u mycontainer.serviceHäufige Ursachen:
Restart=-PoliciesSystemd erschwert nichts – es zeigt glasklar, was nicht startet.
Blockierte Zugriffe finden sich in:
ausearch -m avcoder:
journalctl -t setroubleshootLogs:
journalctl | grep DENIEDProfile checken:
apparmor_statusEin Container, der einen verbotenen Systemcall nutzt, stirbt sofort mit „Operation not permitted“.
Erkennen:
strace -p <PID>wenn die letzte Ausgabe „EPERM“ oder „ENOSYS“ ist → Seccomp.
Ein erprobtes Modell für systematische Diagnose:
Dieses Modell reduziert Diagnosezeit drastisch.
Troubleshooting in Podman-Umgebungen ist keine Kunst, sondern ein strukturierter Prozess. Die Kombination aus direkten Kernel-Interaktionen, transparenter Prozesssicht und klaren Logs ermöglicht eine Diagnosequalität, die weit über daemonbasierte Systeme hinausgeht – sofern man die richtigen Werkzeuge und Denkmodelle konsequent einsetzt.