Tags sind die symbolischen Zeiger auf Images. Sie geben einer flüchtigen Entwicklerversion einen Namen, markieren einen stabilen Build für die Produktion oder definieren einen Zwischenstand für Tests. In der Praxis entscheidet die Tagging-Strategie darüber, ob ein Deployment nachvollziehbar bleibt oder ob es im Chaos der Varianten und Kurzschlüsse endet. In produktionsnahen Architekturen ist Tagging ein Governance-Thema, kein kosmetisches Detail.
Ein Tag ist grundsätzlich ein Verweis, kein Zustand. Sobald man ein neues Image unter demselben Tag veröffentlicht, verschiebt sich dieser Verweis auf eine neue Manifest-Referenz. Das gilt gleichermaßen für Rootless-Umgebungen, lokale Builds und Registries.
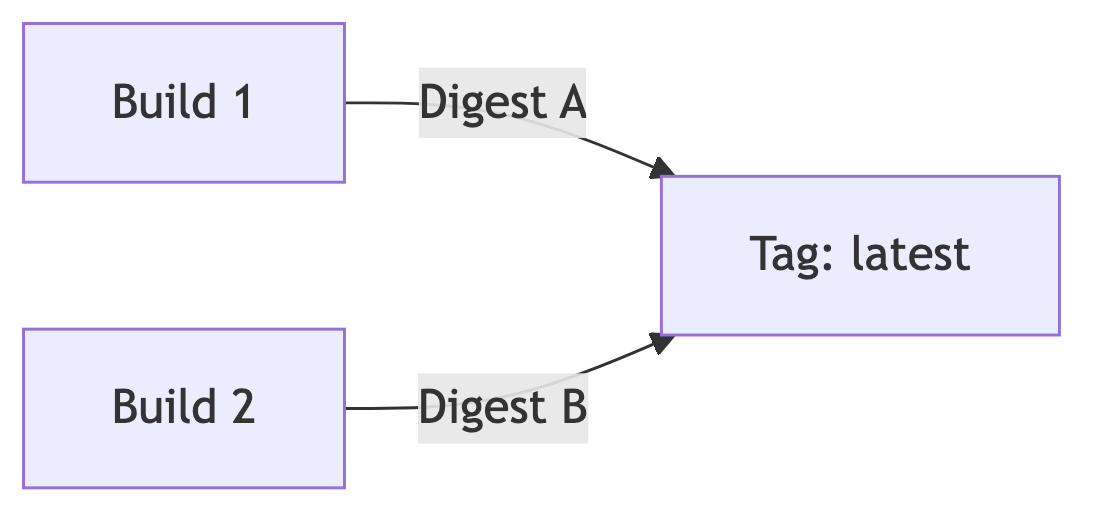
Ein häufiger Irrtum ist die Annahme, dass der Tag selbst eine Version darstellt. Er ist lediglich ein Alias für einen Digest, und dieser Digest repräsentiert den unveränderlichen Inhalt eines Images.
Die Realität im Alltag: der Tag ist bequem. :latest
wirkt harmlos, ist aber gleichzeitig das gefährlichste Tagging-Konstrukt
in produktiven Zusammenhängen, weil es keinerlei deterministische
Aussage trifft.
Der Tag bleibt der gleiche, der Inhalt wechselt. Für Entwickler akzeptabel, für Deployment-Pipelines problematisch.
Der eigentliche Schlüssel eines Images ist der Digest, typischerweise als SHA-256 dargestellt. Er identifiziert den vollständigen Inhalt einer Manifest-Liste einschließlich aller Layer. Keine Registry, kein Build-Tool und kein Deployment-Mechanismus interpretiert diesen Digest – er ist absolut.
Das bedeutet: ein Deployment, das unter Verwendung eines Digests ausgeführt wird, ist reproduzierbar. Ein Deployment über Tags ist abhängig von Timing, Registry-Zuständen oder automatisierten Prozessen, die den Tag unbemerkt weitergeschoben haben könnten.
Deshalb nutzen gut kontrollierte CI/CD-Systeme Digests als Vertragsgrundlage. Tags dienen lediglich der menschlichen Orientierung oder dem Routing von Image-Flows.
Semantic Versioning (SemVer) ist im Code-Alltag etabliert, doch im Image-Kontext wird es oft unkritisch übernommen. Dabei unterscheiden sich die Mechanismen: während Bibliotheken und Artefakte in SemVer typischerweise fortlaufend geführt werden, kann ein Image mehrere SemVer-Zweige gleichzeitig bedienen.
Ein Beispiel: release-branch: app:1.7.4
hotfix-branch: app:1.6.12 feature-branch:
app:1.8.0-rc1
Registry-Tags können diese Vielfalt darstellen, ohne dass sie sich gegenseitig widersprechen. Dennoch sollte man SemVer nur dann konsequent einsetzen, wenn die Build-Pipeline wirklich versionierte Releases erzeugt – nicht als Ersatz für einen Branch-Namen.
Moderne GitOps- und CI-Systeme benötigen häufig diverse Tagging-Layer, die die Build-Realität widerspiegeln. Drei Modelle haben sich im produktionsnahen Umfeld etabliert:
Jeder Build, selbst ein kleiner Bugfix im Feature-Branch, erhält eine eindeutige Buildnummer:
app:build-4721 api-service:2024-11-22T14-07-31
Der Vorteil: jede Pipeline erzeugt eindeutig identifizierbare Images. Der Nachteil: menschlich kaum lesbar.
Der Tag folgt dem Git-Branchnamen:
app:main service:develop payment:feature-add-webhook
Dies ist technisch sauber, aber gefährlich, wenn man versehentlich produktive Deployments aus nicht stabilen Branches anstößt.
Stabile, signierte und geprüfte Images erhalten einen Release-Tag:
app:1.4.0 app:1.4.0-hotfix1
Dieses Modell ist am besten geeignet für produktive Deployments.
Eine Registry kann diese drei Modelle gleichzeitig beherbergen. Entscheidend ist nur, dass Deployments definierte Regeln verwenden.
Ein einzelner Digest kann mehrere Tags besitzen. Das macht es möglich, ein Release gleichzeitig als:
app:1.4.0app:stableapp:productionzu kennzeichnen. Wichtig ist dabei nur, dass man die semantische
Bedeutung der Tags definiert. stable bedeutet im einen Team
„für QA geprüft“, in einem anderen „für Produktion freigegeben“.
Die Kunst liegt in der Konsistenz: sobald Teams Tags unterschiedlich interpretieren, entsteht das sogenannte Tag-Drift-Problem – ein Build, der unter verschiedenen Namen durch Umgebungen wandert und dabei seine Bedeutung variiert.
Tagging darf nicht manuell erfolgen – zumindest nicht im produktionsnahen Szenario. CI/CD-Systeme wie GitLab CI, GitHub Actions, Argo Workflows oder Tekton erzeugen Tags deterministisch und generieren zusätzliche Metainformationen wie Buildzeitpunkte oder Git-Commit-Hashes.
Ein robustes Muster ist das Dual-Tagging:
1.5.2)sha-9b12f3cd)Damit bleiben Images identifizierbar, auch wenn die Version später erneut vergeben oder korrigiert wird.
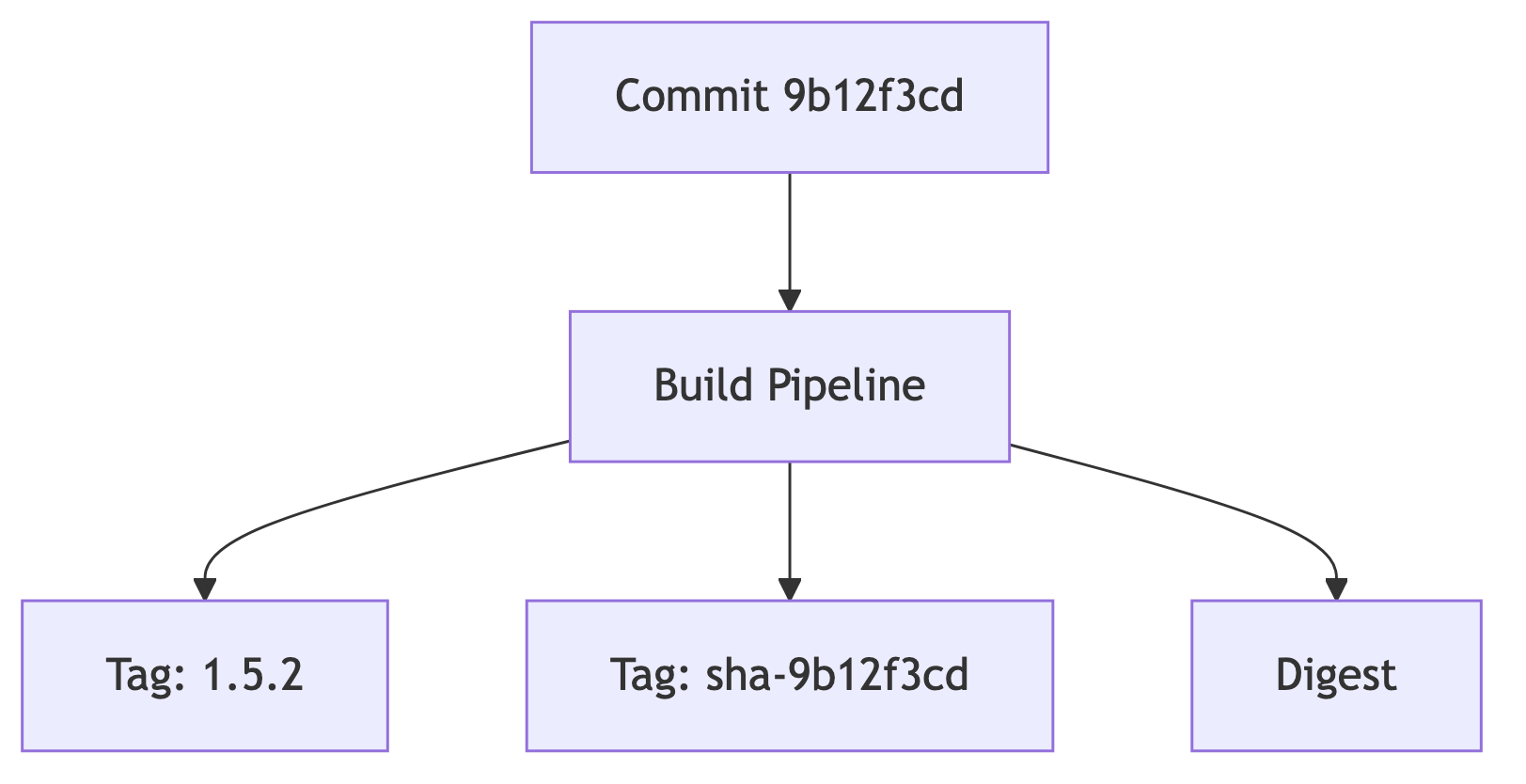
Die Deployment-Systeme sollten im Idealfall nur mit dem Digest arbeiten. Tags dienen lediglich dazu, die Orientierung zu behalten.
Kollisionen entstehen, wenn mehrere Systeme gleichzeitig Schreibrechte auf dieselben Tags besitzen. Ein klassisches Beispiel ist ein Shared Runner, der parallel Jobs ausführt und dieselben Tags erneut setzt.
Vermeiden lässt sich das durch:
latestGerade GitOps-Workflows mit ArgoCD setzen konsequent auf Digest-basierte Promotions, wodurch Kollisionen technisch ausgeschlossen werden.
Sobald ARM64 und AMD64 koexistieren, wird Tagging komplexer. Ein Tag verweist dann nicht mehr auf ein einzelnes Image, sondern auf eine Manifestliste, die wiederum mehrere Varianten referenziert.
Teams müssen in solchen Konstellationen klar definieren, ob Tags plattformübergreifend oder plattformspezifisch sein sollen:
app:1.4.0 → Manifest mit AMD64 & ARM64app:1.4.0-amd64 → spezifisches Imageapp:1.4.0-arm64 → spezifisches ImageBeide Varianten sind legitim. Für gemischte Dev-Umgebungen empfiehlt sich die Manifest-Variante, für hochspezialisierte Produktionsumgebungen eher die Architektur-spezifische.
In größeren Organisationen entwickeln sich Tags schnell zu
informellen Kommunikationsmustern. Ein Tag wie review-ready
ist technisch gesehen völlig legal, hat aber organisatorische Bedeutung.
Das gilt auch für Tags, die Deploymentprozesse steuern, etwa
canary, blue, green.
Solche Muster sind mächtig, aber riskant. Sobald Teams beginnen, organisatorische Zustände über Tags zu transportieren, muss es Regeln geben. Eine nicht dokumentierte Tag-Kultur degeneriert schnell in eine schwer durchschaubare Semantiklandschaft.
Ein pragmatischer Ansatz: Tags müssen kontrolliert geschrieben werden (CI/CD), und ihre Bedeutung muss projektweit festgelegt sein. Alles andere führt zu Deployment-Anomalien, die schwer rückverfolgbar sind.